En ces temps (confinés) de fêtes, j’ai pu prendre le temps de m’extraire de mon métier chronophage pour m’amuser un peu à la maison. Comme c’est Noël, je vous fais le cadeau de partager mon expérience, comme ça Xavier Niel vous revendra ce service dans quelques mois (comme on est en France, je précise pour protéger mon éditeur que c’est de l’humour ni blanc, ni noir).
J’ai choisi l’abonnement Free avec la freebox delta. Un peu cher mais qui permet finalement d’avoir un réseau 10Gb/s à la maison sans se ruiner. A part cela et le NAS intégré, la Delta restait un système relativement basique jusqu’au moment où les développeurs de Free ont eu la bonne idée d’implémenter le service KVM. Il permet de faire tourner des machines virtuelles… sur la box. L’idée est alors d’aller plus loin dans les services proposer par une box et par exemple mettre en place un vpn moderne (dans un prochain article) ainsi qu’un bastion (ou jumpbox). Un bastion va permettre de nous connecter au serveurs de notre réseau privé sans avoir à ouvrir un port sur l’extérieur, avec une double authentification. J’ai choisi ici de tester un bastion avec Teleport. Je vous laisse découvrir ces avantages avec Kubernetes, les Web Applications ou les Databases… je vais faire simple et rester sur du SSH over https.
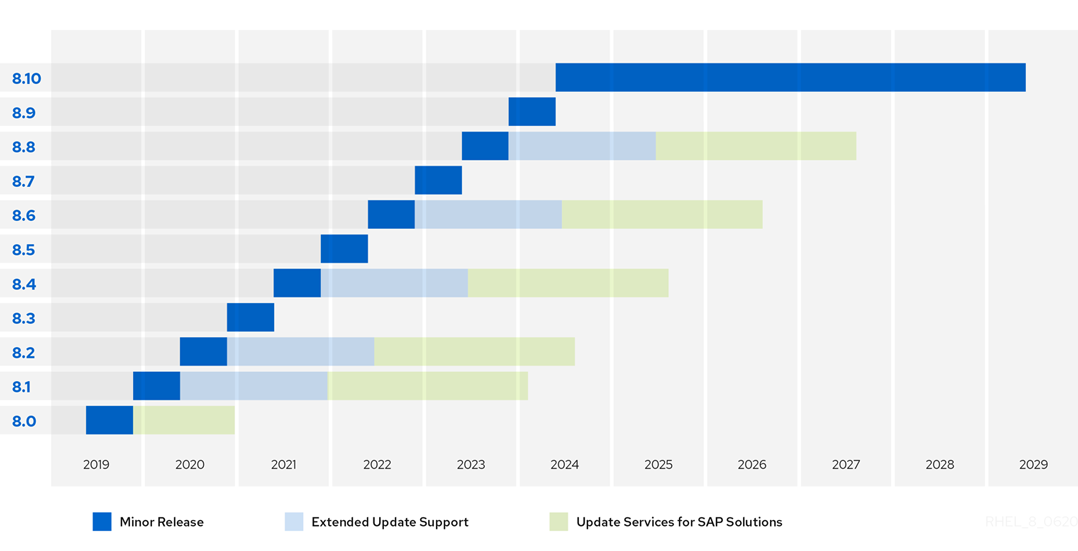
Lors du dernier web-séminaire de RedHat, nous avons la confirmation du détail du cycle de vie des versions antérieures et actuelles de Linux RedHat. En résumé, et nous le savions déjà, la fin de support des versions antérieures à 8.0 depuis aout.
Version
General availability
Full support ends
Maintenance Support 1 ends
Maintenance Support 2 ends
9
A venir
A venir
8
07/05/2019
8.0 (se termine le 31/12/2021) 8.1 (se termine le 30 novembre 2021) 8.2 (se termine le 30 avril 2022) 8,4 (se termine le 30 mai 2023)
N/A
8.0 (se termine le 31/12/2021) 8.1 (se termine le 30 novembre 2021) 8.2 (se termine le 30 avril 2022) 8,4 (se termine le 30 mai 2023)
RedHat nous confirme les fins de supports niveau 2 pour ces mêmes versions pour mai 2021 concernant les architectures non Intel/AMD; et enfin juin 2024 pour Intel/ADM.
RedHat vend évidemment sa solution Ansible pour pouvoir effectuer les migrations rapidement des systèmes anciens ou en utilisant son outil facilitant cette dernière: LEAPP. LEAPP est bien prêt pour passer en version 8.0 les anciennes versions de RedHat EL.
Concernant le cursus de certification RedHat 8.0, il reste inchangé…
L’accès au support technique dépend du niveau de service inclus dans votre abonnement Red Hat Enterprise Linux.
Red Hat peut choisir, à titre de mesure temporaire, de résoudre ces problèmes catastrophiques ayant un impact significatif sur l’activité des clients avec un correctif pendant la création de l’avis d’errata de correction de bogues (RHBA).
L’activation matérielle native est fournie par le rétroportage des pilotes matériels, etc., vers la version appropriée de Red Hat Enterprise Linux. L’activation matérielle à l’aide de la virtualisation est obtenue en exécutant une version antérieure de Red Hat Enterprise Linux en tant qu’invité virtuel sur une version plus récente de Red Hat Enterprise Linux. Consultez la description de la virtualisation ci-dessous pour plus de détails. REMARQUE : la certification matérielle (y compris les limites matérielles associées) s’applique à la version de Red Hat Enterprise Linux utilisée comme hôte.
L’activation matérielle native dans la phase 1 du support de maintenance est limitée à l’activation matérielle qui ne nécessite pas de modifications logicielles substantielles. Consultez la description du support de maintenance 1 ci-dessous pour plus de détails.
Les améliorations logicielles sont des ajouts de nouvelles fonctionnalités au-delà de la correction de défauts ou de l’activation de fonctionnalités existantes sur une nouvelle génération de matériel.
Les versions majeures sont le principal vecteur d’améliorations logicielles importantes, bien que des améliorations logicielles à faible impact puissent également être fournies dans les versions mineures.
La prise en charge étendue des mises à jour (EUS) et la prise en charge du cycle de vie étendu (ELS) sont disponibles en tant que modules complémentaires facultatifs. Voir les descriptions EUS et ELS ci-dessous.
Pour les installations existantes uniquement. Voir les détails ci-dessous pour d’autres limitations.
Ce n’est pas nouveau, mais beaucoup d’ingénieur en informatique ou développeur cherche perpétuellement la bonne configuration pour construire son serveur pour un lab ou plus.
La problématique est que l’encombre d’un serveur au format tour ou rack est avéré. Si l’on cherche à se retrouver seul chez soi avec son serveur, au lieu de la personne avec qui nous vivons, c’est la bonne démarche !
Après une configuration à base de Shuttle et d’intel I7-8700 créée en 2017, je vous propose un nouveau challenge: Un VRAI serveur AMD en format Mini-ITX. Vous allez me rétorquer, “Pffffuu, facile….”. Mais là je vous parle d’un VRAI serveur avec une carte serveur sans l’équipement de carte vidéo. “Aahhhh ?”. Eh bien oui ! 🙂
Après sa fameuse carte mère X470D4U au format ATX, ASRock Rack, la filiale d’ASRock, a publié courant janvier une nouvelle version de cette fameuse carte mère. Plus rapide et pourvu du chipset X570 devenu un standard pour les cartes mères à base de processeurs AMD. Mais cela n’est pas tout. Cette carte est au format Mini-ITX.
Cette nouvelle au final avec les problématiques de COVID, à pris beaucoup…beaucoup de retard sur la production venant de Chine. Les premières livraisons sont arrivées au compte-gouttes courant Juin dans certains pays en Europe, et Juillet/Aout en France.
Pour couronner le tout, certains composants comme les alimentations se sont fait attendre également. Autant dire que les approvisionnements sont tendues à cause de ces épisodes d’épidémies et partout dans le monde.
Voici donc un exemple de configuration que je vous propose en versus Mini-ITX.
Le cahier des charges
Un serveur avec un processeur AMD et dépassant 10 cœurs. Pas de blocage d’évolution de la RAM à 32 ou 64GB La possibilité de mettre plus de deux disque de stockage Un budget raisonnable pour ce genre de configuration
La carte mère
Cette X570D4I-2T est une bombe, et propose tous de sa petite sœur la X470. Attention cependant, cette carte mère est le premier centre de coût après le processeur. Comptez plus de 300€.:
X570D4I-2T
1 socket AMD AM4 pour processeur AMD Ryzen 3000 4 Slots mémoire DDR4 2133/2400/2666/2933 MHz Dual-Channel (128 Go max.) 8 SATA 6Gb/s (par OCulink) avec le support RAID 0/1/10 1 x M.2 PCIe 4.0 x4 / SATA 6 Gbps 1 port PCI-Express 4.0 16x 2 LAN 10 GbE Intel X550-AT2 1 port LAN mangement IPMI Realtek RTL8211E 1 Contrôleur Aspeed AST2500
Et oui, cette carte serveur possède sa carte graphique. Inutile de monopoliser un port PCI pour une carte graphique, car comme vous le savez, seul les AMD de la série Vega intègre le processeur graphique. Un sacré gain de place, de consommation. Et il nous reste un port PCI utilisable pour soit une carte graphique dédié pour du calcul GPU ou autre.
Il s’agit bien ici d’une carte mère serveur, car il y a la présence d’un BMC, car comme on peut le voir, un troisième port Ethernet est disponible. Il s’agit d’un port de management qui permet, comme beaucoup de carte mère serveur de prendre la main à distance (RSA, iLO, et cie). Et surtout de démarrer la carte mère et ses périphériques.
Add’On
Pour ajouter un petit plus (qui existait dans la configuration Shuttle), une carte Wifi en port PCI avec un chipset Intel, et … une puce bluetooth. De quoi être complet, non !?!
Le processeur
Deuxième centre de coût.
Mon objectif était de monté en puissance après ma configuration Shuttle à base d’Intel I7-8700. Ainsi, de 12 Thread sur 6 Cœurs, j’ai fais le choix rapport/prix de passer à 12 Cœurs 24 Thread, soit doubler le compute. Les EPYC étant trop cher, j’ai sélectionner le Ryzen 9 3900X 3800MHz.
La RAM
Troisième centre de coût. Le choix important et doit-être en compatibilité avec les recommandations constructeurs. Deux barettes Crucial CT2K32G4SFD8266 propose ainsi 64 GB de RAM. Ainsi deux emplacements reste libre pour monter à 128GB la capacité maximale mémoire.
L’alimentation
Pour faire fonctionner cela, une bonne alimentation au format TFX, car au format Mini-ITX, c’est le format implicite. J’ai choisi un bon rendement pour jouer la carte budget électrique et éviter des pertes dû au mauvais rendement. La TFX Power 2 300W Gold de chez BeQuiet me semblait une évidence pour rester dans un budget convenable. 300W, cela parait faible, mais cela est très suffisant, a moins d’utiliser des disques dur mécanique)
Le boitier
C’est très secondaire, mais au final, non. Il va accueillir tous l’ensemble et doit-être d’encombrement minimal. J’ai choisi le boitier BU12 de Chieftec, bien sur sans l’alimentation. Le boitier est de bonne facture pour un prix très raisonnable. Si on cherche à héberger beaucoup de disque dur il faudra changer pour un boitier un peu plus haut. Pour mon besoin, je suis parti pour deux unités à fortes capacités. (Nous en parlerons plus tard)
BU12 / Vue de derriere
BU12 / Vue de face
Ce boitier possède des emplacements 2,5″, 3,5″ et un pseudo 5 1/4″. Avec des berceaux d’adaptations à prix modique, il est donc possible de mettre en deux à quatre disque 2,5″.
Le Refroidissement
C’est un choix important pour éviter d’avoir trop de bruit et avoir une ventilation efficace. Par rapport à la hauteur du boitier, le choix est très dirigé.
C7 Cu
ATTENTION, ASRock impose un montage des ventilateurs au format LGA15xx, alors que le processeur est au format M2.
Certains constructeur de système de refroidissement propose des ventilateurs, ou ventirad pour les puristes, adaptables pour de nombreux format et cela peut import le socket du processeur.
C’est le cas du C7 de chez Cryorig, qui possède un look très sympa, sans cloisonnement qui provoque lorsque le ventilateur se voile, des bruits de frottement. La hauteur de ce ventirad nous laisse encore un petit de mou.
Le stockage
Comme je vous l’ai dit, j’ai choisi deux disques SATA SSD à fortes capacités. Selon son besoin, ils pourront être montés en RAID1 ou non en fonction. J’ai choisi un volume par disque Segate Baracuda 120 SSD. Ce choix est le meilleur compromis/prix avec IO supérieurs à Western Digital ou Crucial par exemple.
Enfin pour éviter de monopoliser l’un de ces pour le système de virtualisation, un disque M2 de 250 GB WD blue que je possédais. Très largement suffisant.
L’intégration
La carte mère s’intègre sans complication sur le boitier. C’est côté alimentation que l’intégration doit-être soignée, car la place disponible est faible. Notamment près du ventilateur du boitier. Une attention toute particulière est aussi sur le raccordement. Fourni avec l’alimentation TFX, BeQuiet! propose un adaptateur ATX vers ATX 12V. Il ne faut pas non plus oublier l’alimentation 12v du CPU, sinon la carte mère s’allumera de facto, mais sans CPU rien ne fonctionnera et sans aucune alerte sur la partie BMC.
Comme on peut le voir sur les illustrations, le raccordement des unités de disques de stockage SATA s’effectue par un câble OnLink. Attention ce câble est assez fin et peu, vite s’abimer. Via ce câble, quatre connexions SATA sont disponibles.
ATTENTION également, ASRock recommande d’utiliser les câbles d’alimentations venant de l’alimentation à découpage TFX et non de la carte mère pour éviter des dégradations de la carte mère. Tous dépends de l’alimentation utilisée ATX ou ATX12V.
Installation de l’hyperviseur
Aspeed AST2500 oblige, il faudra se contenter d’un port vidéo VGA. Mais cela n’est pas forcément utile, car nous disposons de notre BMC. Et là tout se fait à distance ! Précaution, tout de même, utilisez la version Java de la prise à distance. Cela vous permettra d’avoir plus d’options à disponibilité.
Cela parait simple, mais il y a toujours des mauvaises estimations de compatibilité avec un hyperviseur ou un autre.
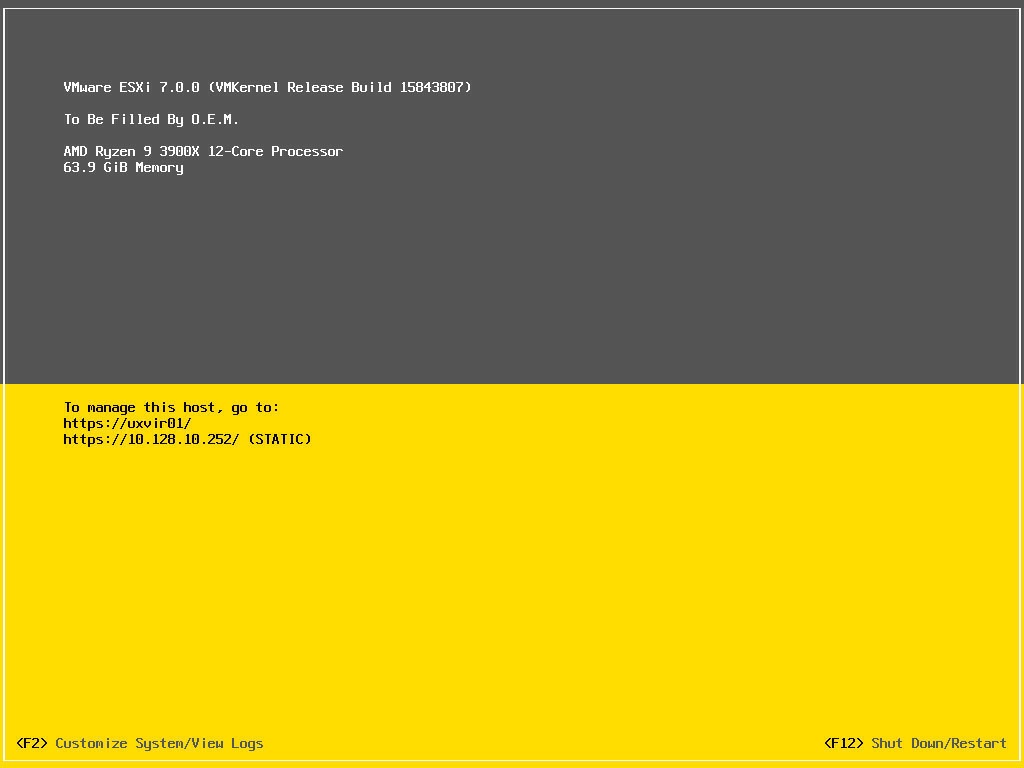
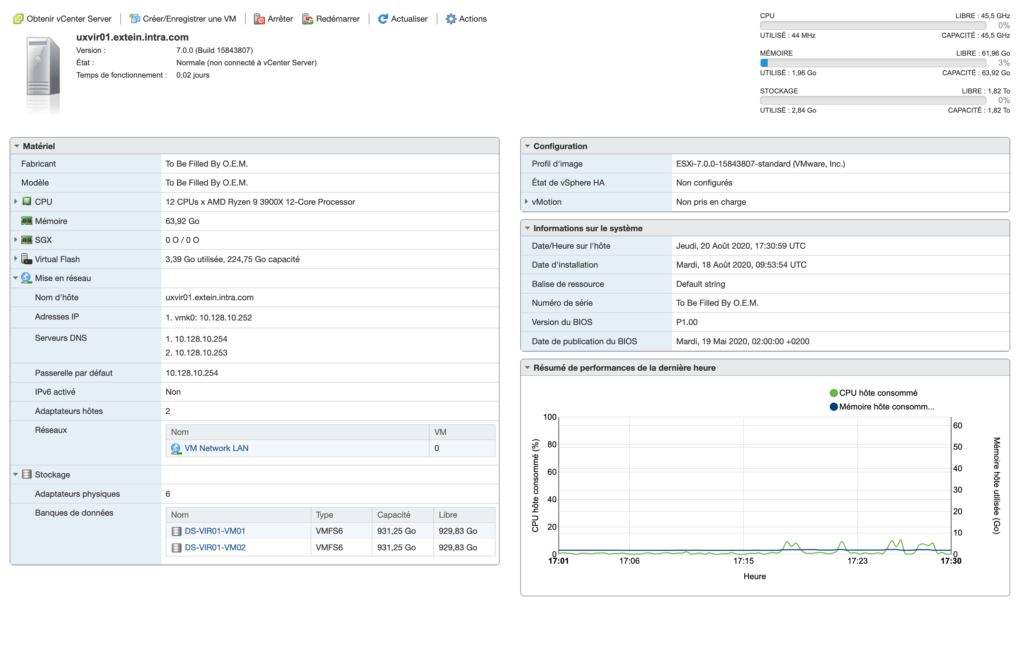
ESXi 7
Avant l’achat, il est évident que des vérifications de compatibilités ont été réalisé notamment avec VMware. L’objectif était également de pouvoir installer un ESXi 7. Comme vous le savez, les drivers de l’ESXi 7 ont été complètement ré-écrit, ce qui ne peut pas forcément arranger les choses.
Force de dire que l’installation passe comme une lettre à la poste. Même la carte WIFI grace à son chipset Intel, est reconnue.
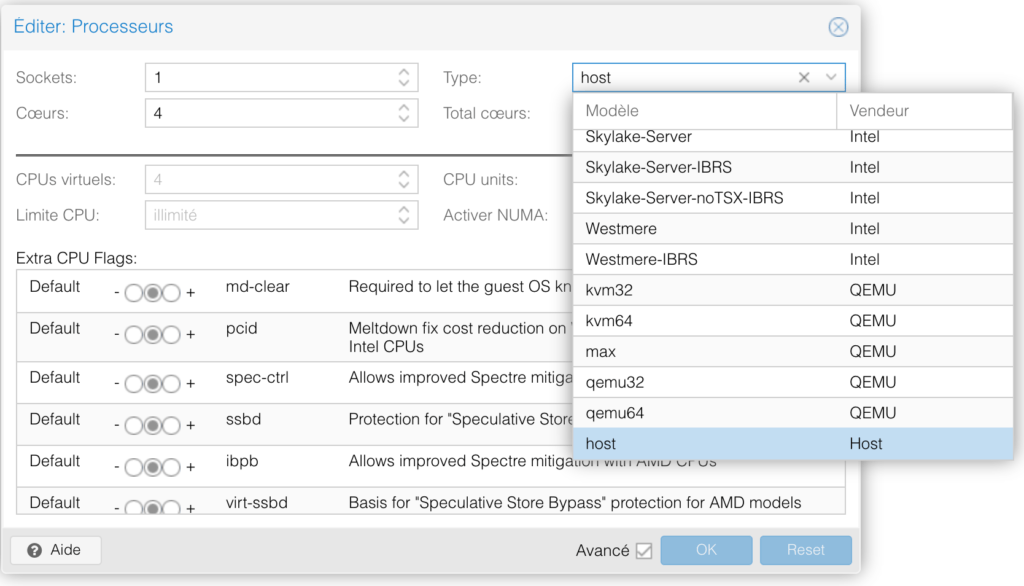
J’ai poussé le bouchon un peu plus loin en virtualisant un hyperviseur Linux, Proxmox. Bien évidement il est important d’activer le partage de l’hyper threading et affecter un nombre suffisant de CPU dédié à cette VM.
Ainsi nous disposons, d’un hyperviseur ESXi, et d’un hyperviseur Proxmox afin de virtualiser des containers LXC/LXD.
Chacun y trouvera son compte.
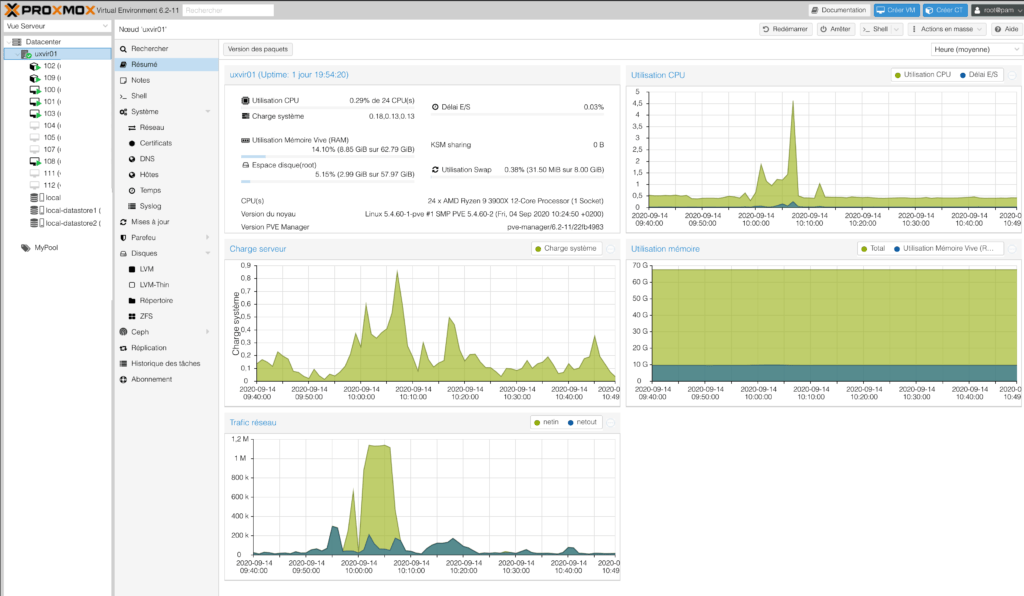
Proxmox 6.2.x
Installer un Proxmox au lieu d’un ESXi 7, ne pose aucun soucis de facto non plus. Noyau Linux oblige, c’est du gâteau ! Là aussi, tout est reconnu. Le petit plus, par rapport à une config Shuttle Intel, aucun besoin de toucher au configuration IOMMU pour éviter des instabilités, car ici TOUT est disponible et fonctionne sans rien faire.
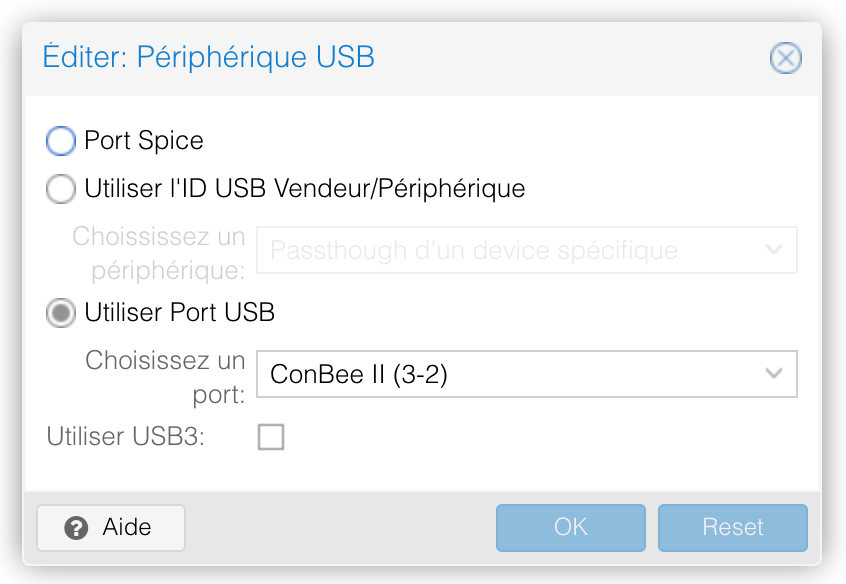
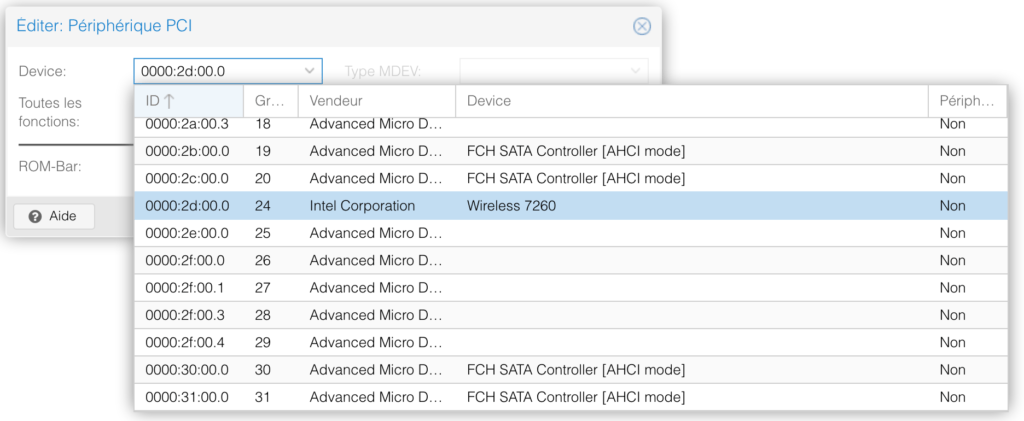
Ainsi le partage en Pass-Thru des add’on PCI ou USB pour une VM, est fonctionnel.
Deux exemples de VM avec leur port PCI ou USB en mode Pass-Thru.
Installer un ESXi en mode Nested ne pose non plus aucun soucis. Il suffit de réserver un certains nombre de ressources CPU en mode CPU-Host par exemple pour profiter d’un hyperviseur VMware sous Proxmox.
Pour rappel sous linux, il est impératif de paramétrer les modules modprobe en fonction du fondeur du cpu:
Activation du support nested
Il faut commencer par contrôler si le paramètre nested est activé ou pas dans le processeur :
cat /sys/module/kvm_intel/parameters/nested
ou
cat /sys/module/kvm_amd/parameters/nested
# N ou 0
S’il est à N ou à 0, c’est qu’il n’est pas activé.
Pour activer l’activer, il suffit de positionner la variable à 1 à l’aide de la commande; Remplacez xxxx par le fondeur du cpu:
Il faut ensuite redémarrer le module kvm. Pour cela il faut que toutes les vms soient arrêtée sur le serveur.
modprobe -r kvm-intel ou modprobe kvm-intel
On vérifie :
cat /sys/module/kvm_intel/parameters/nested
# Y ou 1
Côté hyperviseur, on est prêt !
Coté guest-OS, plus particulièrement l’hyperviseur virtualisé, il est impératif de paramétrer au niveau de l’enveloppe du guest le type de cpu à host.
Puis également, même si ce n’est pas forcément impératif, ajouter le paramètre : args: -enable-kvm dans le fichier de conf de la vm (Par exemple : /etc/pve/qemu-server/106.conf
C’est tout ! Vous voilà prêt pour virtualiser un hyperviseur…Heu mais que dis-je ? 🙂
Bonjour à tous, cela fait un long moment que je n’ai pas eu l’opportunité d’écrire un article. Il y a quelques jours, j’ai eu besoin de relier un object storage OpenStack à un Nextcloud. J’ai décidé ensuite de l’automatiser avec terraform et l’inclure dans un module. Pour ceux qui ne connaissent pas les pratiques Objects Storage, je renvoie au site OpenStack. Comme d’hab, comme je suis chauvin, je vais utiliser un service cloud français : OVH. Bientôt et si le temps me le permet, j’utiliserai ma propre infra OpenStack sur plusieurs nodes : pour ça, j’ai enfin reçu mes cartes mères bi-xeon supermicro, mais tout est à construire, même le hardware donc à suivre…
Le Cloud ou infrastructures en nuage donne un accès partagé à des données ainsi qu’à des programmes qui sont stockés sur un ensemble de serveurs informatiques distants et souvent répliqués sur divers sites géographiques dans différentes régions d’un même pays et/ou à l’internationale.
Comme dirait mon vendeur de téléphone, “on ne va pas se mentir” : je déteste le Cloud. Ça vient de très loin – je me demande même si je faisais de l’informatique – d’une discussion avec une fraîche mouture de Science-Po de l’époque qui me vantait l’avantage du concept “magique” du cloud, et en quoi il était bon que “Mme Michu” n’y comprenne rien. Maintenant que je vois cela de l’intérieur, je dirais que mon sentiment de défiance est renforcé.
Derrière le Cloud il y a du “barre metal”, c’est à dire des serveurs physiques reliés les uns aux autres, très souvent sous Linux, avec une couche d’automatisation complexe qui permet d’offrir des services de plus en plus importants aux clients. Or il est une règle vieille comme le monde : pas d’indépendance sans connaissance… Durant le temps que vous chercherez la technique pour construire des serveurs sur l’infra d’Amazon ou Microsoft, d’autres le passeront à trouver des techniques plus poussées pour vous rendre toujours plus dépendant. Des services rendus propriétaires qui étrangement fonctionnent mieux que le standard opensource… par exemple des bases de données, de la redondance de charge… Le Cloud c’est avec modération, celui qui se sert du Cloud pour des applications critiques est fou, et dans le fond celui qui vend des services Cloud américains aux grands comptes français ne veut pas vraiment de l’indépendance économique française. C’est une situation qui devrait être accompagnée par le politique car dans les DSI, l’argent est bien souvent ROI… et la stratégie sur le long terme se fait rare. Si ces questions liées à la “souveraineté numérique” vous intéressent, je vous invite à lire cet article : Souveraineté numérique : le choix inquiétant fait par la BPI pour l’hébergement des données.
Vous l’aurez compris, je vais prendre un exemple de Cloud bien français même si ce dernier s’étend maintenant dans le monde entier : celui d’OVH. En plus ils utilisent la techno Openstack, ce qui est parfait pour s’initier aux concepts de cloud public/privé. Il faut savoir que le Cloud n’est pas gratuit, 0.01€ vous seront facturés à la création de l’infra ci-dessous, plus si vous décidez de garder le serveur.
Prérequis
Avoir un compte chez OVH et souscrit à l’offre Cloud
Un utilisateur OpenStack
Les variables d’environnement OpenStack
Vos identifiants API et clés d’autorisations OVH
Une clé SSH
L’exécutable Terraform
Les clients OpenStack (nova, glance)
Vous trouverez les pages de tutoriel chez OHV et sur ce site. Normalement pas de soucis majeurs pour effectuer ces opérations, si vous avez néanmoins des problèmes, envoyez-moi un message et je détaillerai ce paragraphe des prérequis.
Utilisation de Terraform pour les instances Cloud public
On va faire très simple, trois fichiers. Un pour la connection à Openstack, un autre pour la création de la machine et son réseau, le dernier pour les variables :
$ tree
.
├── connections.tf
├── simple_instance.tf
└── variables.tf
connections.tf
Rien de bien compliqué ici :
provider "openstack" {
auth_url = "https://auth.cloud.ovh.net/v3.0/"
domain_name = "default"
tenant_name = ""
alias = "ovh"
user_name = "utilisateur_openstack" # vous possédez ces valeurs
password = "le_mot_de_passe" # si vous avez effectué les prérequis
}
simple_instance.tf
Voilà maintenant pour créer un serveur, j’utilise l’adresse IP de la machine d’administration afin de l’autoriser à accéder au serveur Cloud via SSH. Vous pouvez utiliser une autre technique que firewalld, il suffit de changer le script run.sh … Comme d’habitude, j’utilise des images cloud de Fedora Server (ici 32).
resource "openstack_compute_keypair_v2" "mattkey" {
provider = openstack.ovh
name = "mattkey" # A changer : c'est la clé que vous avez préalablement créée dans l'interface openstack OVH
public_key = file("~/.ssh/id_rsa.pub") # C'est la clé que vous avez préalablement créée dans l'interface openstack OVH
}
data "openstack_networking_network_v2" "public_a" {
name = "Ext-Net"
provider = openstack.ovh
}
resource "openstack_networking_port_v2" "public_a" {
name = "test_a_0"
network_id = data.openstack_networking_network_v2.public_a.id
admin_state_up = "true"
provider = openstack.ovh
}
data "http" "myip" {
url = "https://api.ipify.org"
}
data "template_file" "setup" {
template = <<SETUP
#!/bin/bash
# install & configure firewall
dnf install -y firewalld
systemctl start firewalld
systemctl enable --now firewalld
firewall-cmd --permanent --add-service=ssh
firewall-cmd --permanent --add-source=${trimspace(data.http.myip.body)}/32 --zone=trusted
firewall-cmd --permanent --add-service=ssh --zone trusted
firewall-cmd --permanent --remove-service=ssh --zone=public
firewall-cmd --reload
SETUP
}
data "template_file" "userdata" {
template = <<CLOUDCONFIG
#cloud-config
write_files:
- path: /tmp/setup/run.sh
permissions: '0755'
content: |
${indent(6, data.template_file.setup.rendered)}
- path: /etc/systemd/network/30-ens3.network
permissions: '0644'
content: |
[Match]
Name=ens3
[Network]
DHCP=ipv4
runcmd:
- sh /tmp/setup/run.sh
CLOUDCONFIG
}
resource "openstack_compute_instance_v2" "fed-test" {
region = var.region
name = "test-fed-instance"
provider = openstack.ovh
image_name = "Fedora 32"
flavor_name = "s1-2"
user_data = data.template_file.userdata.rendered
key_pair = openstack_compute_keypair_v2.mattkey.name
network {
access_network = true
port = openstack_networking_port_v2.public_a.id
}
}
output "Server_IP" {
value = openstack_networking_port_v2.public_a.all_fixed_ips
}
variables.tf
variable "region" {
type = string
default = "UK1" # cette valeur dépend de votre compte OVH et du fichier openstack .rc
}
Et voilà le tour est joué, théoriquement, l’ip du serveur s’affiche à la fin de l’exécution du `terraform apply`, vous pouvez vous y connecter via SSH avec votre clé privée. Pour tout détruire : `terraform destroy`. Si vous vous souvenez de mes précédents articles, ici ou là, vous pouvez maintenant provisionner la ou les machines avec Ansible.
Derrière ce titre un poil “putaclic” se cache des heures de recherches et des litres de café. Et oui, le réseau et moi ça fait deux… Vous vous souvenez sans doute de mon dernier article portant sur openvswitch, il n’était pas écrit pour rien… généralement quand je commence à fouiller une techno c’est que j’ai une idée derrière la tête.
Jusqu’à présent pour créer un réseau privé, j’utilisais tinc. Je ne vais pas m’appesantir sur ce sujet, mais c’est tout de même assez puissant. Je ne cache pas que dans une logique d’automatisation et d’industrialisation, ce n’est pas franchement sexy. Il faut installer le binaire, le configurer (en mode switch c’est mieux), créer les interfaces tun/tap, les clés, les partager… Il existe des rôles Ansible pour faire le job, vous les trouverez facilement sur Github.
On va s’approcher un peu plus d’un fonctionnement type OpenStack et utiliser les possibilités offertes par OpenVSwitch.
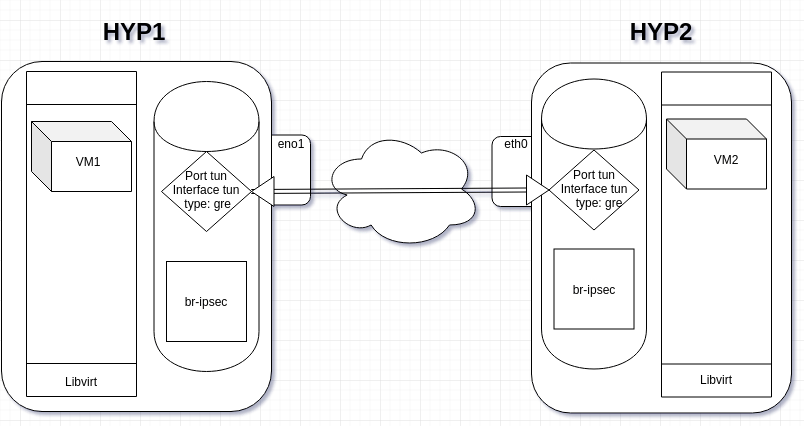
Nous allons créer un bridge interne GRE avec tunnel IPsec :
Pré-requis
Pour ce faire il faut au minimum deux hyperviseurs KVM bare metal, ça fonctionne aussi avec Proxmox et MacOS VMWare (ahahah), OpenStack puisque c’est intégré dans la solution, mais aussi sans rien… Il faut deux IPs joignables qui pointent vers les serveurs. Avoir installé openvswitch, sauf si ça ne vous intéresse pas mais dans ce cas, je me demande pourquoi vous lisez ces lignes.
Configuration
On ne va pas faire une usine à gaz, juste créer des certificats auto-signés avec la cli d’openvswitch sur le premier hôte :
Ensuite on va dire à openvswitch où se trouvent ces fichiers :
ovs-vsctl set Open_vSwitch . \
other_config:certificate=/etc/keys/<hostname1>-cert.pem \
other_config:private_key=/etc/keys/<hostname1>-privkey.pem
A faire sur chacun des serveurs bien sûr et changeant le nom hostname du .pem. C’est terminé pour les certificats et clés. Maintenant la mise en place des bridges ipsec GRE avec openvswitch. Sur l’hôte 1:
ip addr add 192.0.0.1/24 dev br-ipsec
ip link set br-ipsec up
ovs-vsctl add-port br-ipsec tun -- set interface tun type=gre \
options:remote_ip=<ip_de_hote2> \
options:remote_cert=/etc/keys/<hostname2>-cert.pem
ovs-vsctl show
Sur l’hôte 2 :
ip addr add 192.0.0.2/24 dev br-ipsec
ip link set br-ipsec up
ovs-vsctl add-port br-ipsec tun -- set interface tun type=gre \
options:remote_ip=<ip_de_hote1> \
options:remote_cert=/etc/keys/<hostname1>-cert.pem
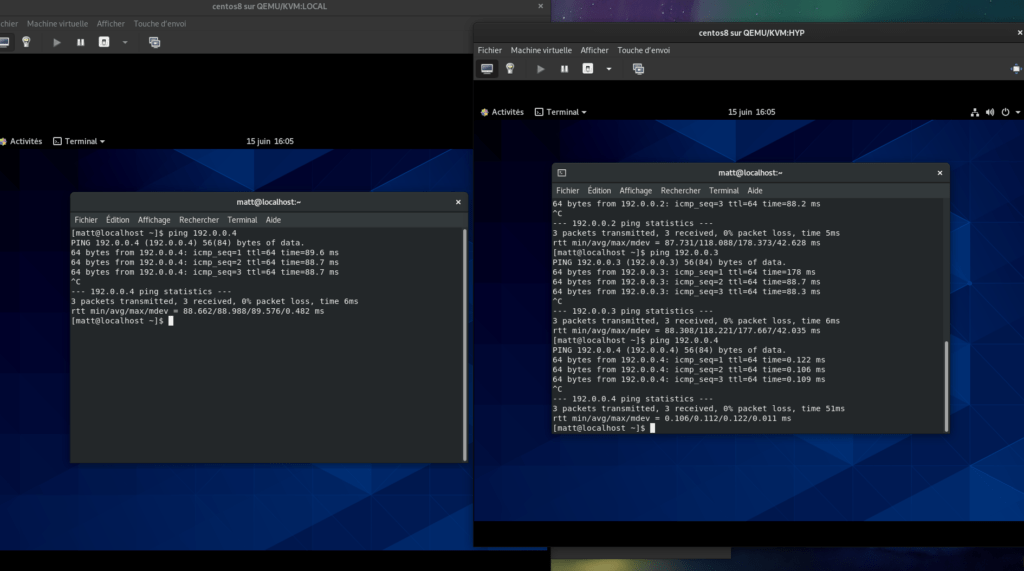
Et maintenant sous vos yeux ébahis depuis l’hôte 2 :
ping 192.0.0.1
PING 192.0.0.1 (192.0.0.1) 56(84) bytes of data.
64 bytes from 192.0.0.1: icmp_seq=1 ttl=64 time=88.9 ms
64 bytes from 192.0.0.1: icmp_seq=2 ttl=64 time=87.6 ms
64 bytes from 192.0.0.1: icmp_seq=3 ttl=64 time=87.8 ms
^C
--- 192.0.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 87.587/88.097/88.926/0.591 ms
Généralisation
Vu que les serveurs sont des hyperviseurs KVM, on va tenter de créer des machines virtuelles qui profiteront du tunnel IPsec. Comme nous l’avons vu dans le dernier article sur openvswitch, il faut intégrer le xml du bridge pour qu’il soit interprété par libvirt :
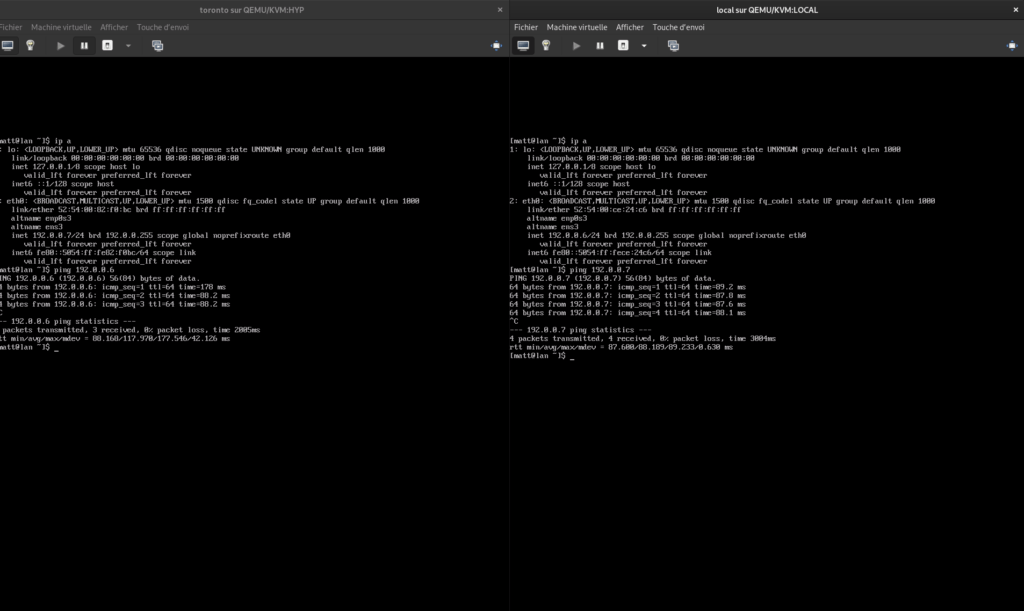
Faites démarrer une vm sur chaque hyperviseur avec comme réseau net-ipsec, donnez-lui une adresse dans ce réseau et pingez.
Ping de deux vms entre Paris et Beauharnois (datacenter OVH)… latence cata…
Automatisation
Pour travailler dans un environnement automatisé, avec Terraform et Libvirt KVM, il faudra utiliser un alias pour le provider (j’ai mis Toronto en hommage à Glenn Gould, le joueur de foot) :
# cat multi_hyp.tf
provider "libvirt" {
uri = "qemu:///system"
}
provider "libvirt" {
alias = "toronto"
uri = "qemu+ssh://<kvm_user>@<ip_address>/system"
}
resource "libvirt_volume" "local-fedora-qcow2" {
name = "fedora-qcow2"
pool = "default"
source = "https://download.fedoraproject.org/pub/fedora/linux/releases/32/Cloud/x86_64/images/Fedora-Cloud-Base-32-1.6.x86_64.qcow2"
format = "qcow2"
}
resource "libvirt_volume" "remote-fedora-qcow2" {
provider = libvirt.toronto
name = "fedora-qcow2"
pool = "default"
source = "https://download.fedoraproject.org/pub/fedora/linux/releases/32/Cloud/x86_64/images/Fedora-Cloud-Base-32-1.6.x86_64.qcow2"
format = "qcow2"
}
resource "libvirt_cloudinit_disk" "commoninit-local" {
name = "local-commoninit.iso"
pool = "default"
user_data = data.template_file.user_data.rendered
network_config = data.template_file.network_config_local.rendered
}
resource "libvirt_cloudinit_disk" "commoninit-remote" {
provider = libvirt.toronto
name = "remote-commoninit.iso"
pool = "default"
user_data = data.template_file.user_data.rendered
network_config = data.template_file.network_config_remote.rendered
}
data "template_file" "user_data" {
template = file("${path.module}/cloud_init.cfg")
vars = {
hostname = "fedora"
fqdn = "lan"
user = "matt"
ssh_public_key = "ssh-rsa AAAA..."
}
}
data "template_file" "network_config_local" {
template = file("${path.module}/network_config_static.cfg")
vars = {
prefixIP = "192.0.0"
octetIP = "6"
}
}
data "template_file" "network_config_remote" {
template = file("${path.module}/network_config_static.cfg")
vars = {
prefixIP = "192.0.0"
octetIP = "7"
}
}
resource "libvirt_domain" "local-domain" {
name = "local"
memory = "2048"
vcpu = 2
disk {
volume_id = libvirt_volume.local-fedora-qcow2.id
}
cloudinit = libvirt_cloudinit_disk.commoninit-local.id
network_interface {
network_name = "net-ipsec"
}
}
resource "libvirt_domain" "remotehost-domain" {
provider = libvirt.toronto
name = "toronto"
memory = "2048"
vcpu = 2
disk {
volume_id = libvirt_volume.remote-fedora-qcow2.id
}
cloudinit = libvirt_cloudinit_disk.commoninit-remote.id
network_interface {
network_name = "net-ipsec"
}
}
terraform {
required_version = ">= 0.12"
}
Avec les fichiers config de cloudinit qui vont bien :
# cat network_config_static.cfg
version: 2
ethernets:
eth0:
dhcp4: no
dhcp6: no
addresses: [ ${prefixIP}.${octetIP}/24 ]
Et les vms se pingent, on peut également s’y connecter en SSH depuis leurs adresses privées sur 192.0.0.0/24 :
Optimisation
Il peut être franchement intéressant d’optimiser en configurant la valeur du MTU. Par exemple sur ma connexion entre mes deux hyperviseurs kvm (Paris et Beauharnois) en passant d’un MTU 1500 à 1554 j’obtiens :
[root@hyp ~]# iperf -c 192.0.0.2
------------------------------------------------------------
Client connecting to 192.0.0.2, TCP port 5001
TCP window size: 325 KByte (default)
------------------------------------------------------------
[ 3] local 192.0.0.1 port 44128 connected with 192.0.0.2 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.2 sec 10.1 MBytes 8.35 Mbits/sec
[root@hyp ~]# ifconfig eno3 mtu 1554
[root@hyp ~]# iperf -c 192.0.0.2
------------------------------------------------------------
Client connecting to 192.0.0.2, TCP port 5001
TCP window size: 325 KByte (default)
------------------------------------------------------------
[ 3] local 192.0.0.1 port 44130 connected with 192.0.0.2 port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.1 sec 264 MBytes 220 Mbits/sec
Voilà pour cet article, reste maintenant à isoler à l’intérieur avec des VLANS, mais aussi VXLAN… dans un futur… proche… si j’ai le temps…
Nous utilisons des cookies sur notre site Web pour vous offrir l'expérience la plus pertinente en mémorisant vos préférences et des visites répétées. En cliquant sur «Accepter», vous consentez à l'utilisation de TOUS les cookies.
Ce site Web utilise des cookies pour améliorer votre expérience pendant que vous naviguez sur le site Web. Parmi ces cookies, les cookies classés comme nécessaires sont stockés sur votre navigateur car ils sont essentiels au fonctionnement des fonctionnalités de base du site Web. Nous utilisons également des cookies tiers qui nous aident à analyser et à comprendre comment vous utilisez ce site Web. Ces cookies ne seront stockés dans votre navigateur qu'avec votre consentement. Vous avez également la possibilité de désactiver ces cookies. Mais la désactivation de certains de ces cookies peut avoir un effet sur votre expérience de navigation.
Les cookies fonctionnels aident à exécuter certaines fonctionnalités telles que le partage du contenu du site Web sur les plates-formes de médias sociaux, la collecte de commentaires et d’autres fonctionnalités tierces.
Les cookies de performance sont utilisés pour comprendre et analyser les principaux indices de performance du site Web, ce qui contribue à offrir une meilleure expérience utilisateur aux visiteurs.
Cookie
Description
YSC
Ces cookies sont définis par Youtube et sont utilisés pour suivre les vues des vidéos intégrées.
Les cookies analytiques sont utilisés pour comprendre comment les visiteurs interagissent avec le site Web. Ces cookies aident à fournir des informations sur les mesures du nombre de visiteurs, du taux de rebond, de la source du trafic, etc.
Les cookies publicitaires sont utilisés pour fournir aux visiteurs des publicités et des campagnes marketing pertinentes. Ces cookies suivent les visiteurs sur les sites Web et collectent des informations pour fournir des publicités personnalisées.
Cookie
Type
Durée
Description
IDE
1 an et 24 jours
Utilisé par Google DoubleClick et stocke des informations sur la façon dont l'utilisateur utilise le site Web et toute autre publicité avant de visiter le site Web. Ceci est utilisé pour présenter aux utilisateurs des publicités qui les concernent en fonction du profil de l'utilisateur.
test_cookie
15 minutes
Ce cookie est défini par doubleclick.net. Le but du cookie est de déterminer si le navigateur de l'utilisateur prend en charge les cookies.
VISITOR_INFO1_LIVE
5 mois et 27 jours
Ce cookie est défini par Youtube. Utilisé pour suivre les informations des vidéos YouTube intégrées sur un site Web.
Les cookies nécessaires sont absolument essentiels au bon fonctionnement du site Web. Ces cookies assurent les fonctionnalités de base et les fonctions de sécurité du site Web, de manière anonyme.
Cookie
Type
Durée
Description
__cfduid
1 month
Le cookie est utilisé par les services cdn comme CloudFare pour identifier les clients individuels derrière une adresse IP partagée et appliquer les paramètres de sécurité par client. Il ne correspond à aucun identifiant d'utilisateur dans l'application Web et ne stocke aucune information personnellement identifiable.
cookielawinfo-checkbox-performance
1 an
Ce cookie est défini par le plugin GDPR Cookie Consent. Le cookie est utilisé pour stocker le consentement de l'utilisateur pour les cookies dans la catégorie «Performance».